
About a year ago, the other half had a computer that malfunctioned in a particularly nasty way.
All of the data from that computer was essentially wiped because the computer itself managed to rewrite data enough times on an SSD that it killed the drive. FYI. Solid State Drives have a finite lifespan that is dictated by the number of times data is written to them.
The other half’s computer managed to kill not one but two SSD drives in 6 months. Wow! that’s a whole lot of rewriting of data. 20 years worth in 3 months.
The upshot of all of this is that I ended up digging data up from backups, and places on the network where they’d stored data. This doesn’t sound like much of an issue until you realize that the other half stores data in a completely random way.
This is not surprising since hardcopy data is stored in exactly the same way in odd little places all around the house.
After I’d consolidated all the data I could recover into a single group of folders on the server, I said, “Okay that’s all I can do, you’re going to have to sort through and delete duplicates and what you don’t need.”
That was over a year ago. Guess what? Nothing has been touched since the important documents got transferred to the new computer.
Here’s a lovely chart showing how much data is needlessly occupying space on the server.
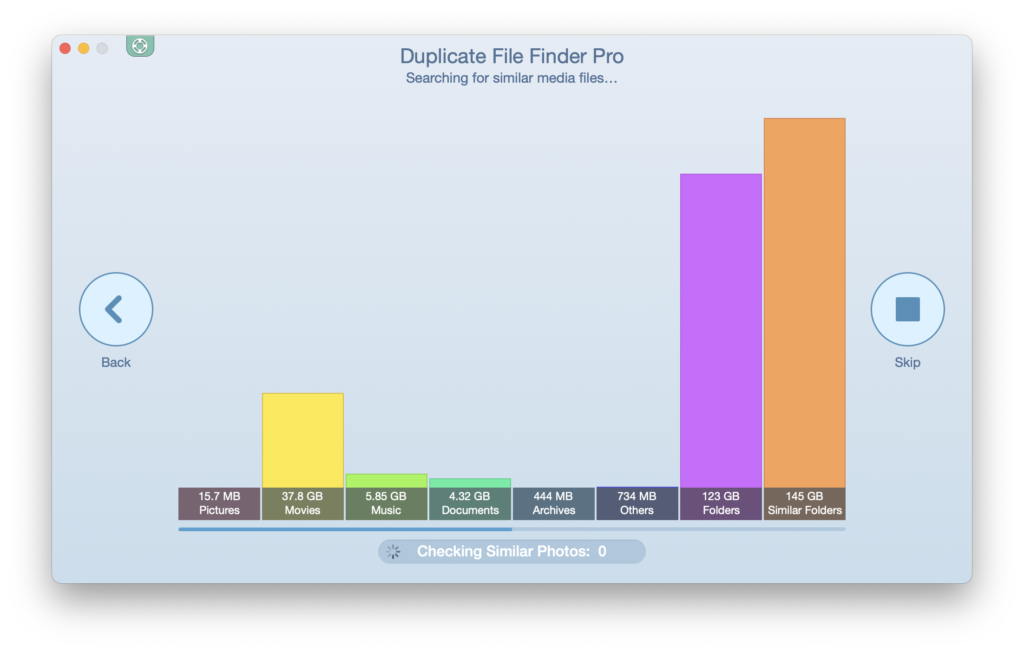
These numbers are astounding. Gigabytes of duplicate data? Really?
Well, since none of this has been touched in over a year. I’m going to clean house!
This is going to take a really long time. I’m not even going to bother to examine files, I’m going to use a utility to merge folders and delete duplications.
Whatever is lost will probably be of no consequence since it wasn’t important enough to look through in the first place.
The fact is, there’s no reason to have 5 folders of duplicate information indexed and stored on the server. It’s not that I’m all that worried about space I’ve got tons available. It’s about the possibility of a drive crash and all of this crap would make recovering from a one or two drive malfunction in the RAID array really tedious.
I’m sure that I’ll hear about something being lost, sometime in the future, but I’ll deal with that when/if the time comes.
At this point, I’m curious to see just how the deletion of all of this crap affects the performance of the server. I’m betting that the reduction in size of the index files alone will get me a speed boost.
I just hope the utility can swallow and digest a mountain of redundant data.
I should know in another 12 hours or so.
Now off to deal with some other poop. This time it’s legitimate poo, from the dog. Strangely I don’t mind cleaning the poop from the back yard nearly as much as I mind cleaning up the poop on the server.
Have a great weekend.
Update:
260GB deleted. Probably 100GB more to sort through.
The cleaning application, got lost in the mess. This happened several times.
I finally got annoyed with the utility. I was seriously considering asking for a refund. I went in manually to do the job. Initially I was thinking, “DAMN a human brain will still be needed to do the most basic things!”
Uh Huh…
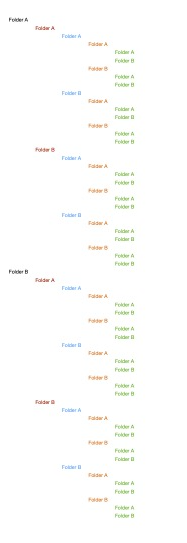
I found that the application was having a problem with folders nested within folders that all had the same names.
It looked like the image to the right.
But in each one of the subfolders, there were files. Some of these files were originals and some of them were duplicates.
This diagram shows a recursion only 5 levels deep. Something like 63 directories and what I was looking at was in some cases 7 levels deep. It was not uncommon for there to be 1000’s of files in each directory.
As you can imagine, it got out of hand very quickly. Especially when you consider that many of the file names were duplications.
I’d been annoyed at the utility for not being able to keep it all straight. But I was far less annoyed when I realized that I, (The Human,) had gotten lost more than once in this digital house of mirrors.
As a interesting aside, It took me two different applications to create even this simple representation. One of the applications flat out refused to engage in the illogic and crashed.
The second application was somewhat uncooperative but eventually allowed me to create it, then save it as a PNG.
I’m no longer annoyed at the duplicate finding utility that threw up its hands. Even trying to create the representation was harder than I thought it would be. I could picture in my head what I wanted to show, but translating that kind of irrationality to something clear was… Odd.
In the case of the utility, I very much doubt that the programmer who created it even considered that someone would do something like this. So I still think the utility was worth what I paid for it.
Looking at the recycle bin, it looks as though the utility handled 4 levels of recursion without a complaint.
It’s because of this kind of thing that I personally am a bastard when it comes to training computer users on the importance of reasonable directory structures. I’ve always said that if you need nested directories more than five levels deep, you’re doing something wrong.
Obviously, there are exceptions to this rule. Computers can keep track of much deeper nesting, but non-technical average human beings??? More than five levels down, you’re asking for files to be “lost” and setting yourself up to chew hard disk space with duplicate files that will never be accessed again.
Yet again… There’s usually a good reason for me doing things the way I do.
So that was my Saturday… I hope yours was more fun and less, uhh… interesting.